
Introduction
When you send a query to PostgreSQL, it will undergo several processing stages in the backend. Each of these stages has different responsibilities to ensure that you receive correct responses in shortest amount of time possible. Yes, they can be quite large and complex to fully understand but I believe it is important for PostgreSQL developer like you to at least understand their roles in handling a query. In this blog, I will give an overview of each query processing stage, their roles and significance in PostgreSQL architecture.
The 5 Query Processing Stages

Parser
PostgreSQL’s parser is created using the lex (Flex lexical analyzer) and yacc (bison parser) tools. Both are commonly used tools. This is done usually by writing a regular expression definition file, which is then converted into the corresponding C source file structures. These generated source files can be found under src/backend/parser. This conversion action is automatically performed when executing Make when you compile PostgreSQL from source.

short summary:
- Responsible for checking literal syntax errors.
- Generate parse tree.
- Use
flexandbisonto parse query syntax. - The entry point is in
parser/parser.c.
Analyzer
The main purpose of the Analyzer is to check the raw_parsetree structure created by the parser stage.
For example: table name, inserted data type, field name information will be checked for validity. If they exist, PostgreSQL will use the OID number to represent them internally and generate a query tree structure.
short summary:
- Responsible for deeper syntax analysis.
- Access the designated database.
- Check if designated table exists.
- Check the correctness of data formats.
- Convert table names to internal OIDs.
- Generate query tree.
- The entry point is in parser/analyze.c.
Rewrite
The main purpose of Rewriter is to rewrite and optimize the query tree output by the analyzer.
For example: check whether other VIEW or RULE structures are referenced. If so, it will rewrite the statement and translate VIEW and RULE into corresponding statements. It outputs an optimized query tree for the planner module.
short summary:
- Responsible for rewriting query if needed.
- If the query accesses a
VIEWorRULEobject, it will be expanded (or rewritten) according to their VIEW or RULE’s definitions. - The entry point is in rewrite/rewriteHandler.c.
Planner
Responsible for statement execution cost estimation + generating optimal query plans. Different execution methods, also called paths, are calculated based on the statement type, table structure, whether there are indexes and size, etc.
Each path has an estimated cost and the path with the minimum cost is considered the optimal query plan. Finally, an optimal query plan (PlannedStmt structure) is generated and sent to the executor module (executor) to execute it.
The Planner module is relatively complex in PostgreSQL. The development of large functions usually requires certain understanding or even changes to the planner.
get_relation_info() call:
get_relation_info() of plancat.c is an important function in planner’s cost estimation. It tells the planner:
- how many pages there are in the table.
- how many data (tuples) there are.
- how many indexes there are.
- which column is the index key.
- whether there is a foreign table.
- and other information.
These are the basis for planners to estimate costs. It obtains this information through access methods
- Heap access method – Get data table information
- Index access method – Get index related information
short summary:
- Responsible for generating an execution plan.
- Identify all possible methods (or paths) that can lead us to get the results
- Choose the best method that will complete the query in the shortest time.
- The entry point is in optimizer/plan/planner.c
Executor
Main purpose of executor it to run the execution plan generated by the planner. It is actually controlled by the portal module, which is the facilitator of the actual execution. Based on the nature of the execution plan, either the executor or the processUtility will be invoked:
See the illustration below to learn the responsibilities of ProcessUtility and Executor

short summary:
- Execute the query according to the execution plan
- Access several other modules in PostgreSQL backends to complete the query
- The entry point is in executor/execMain.c
What Happens after Executor?
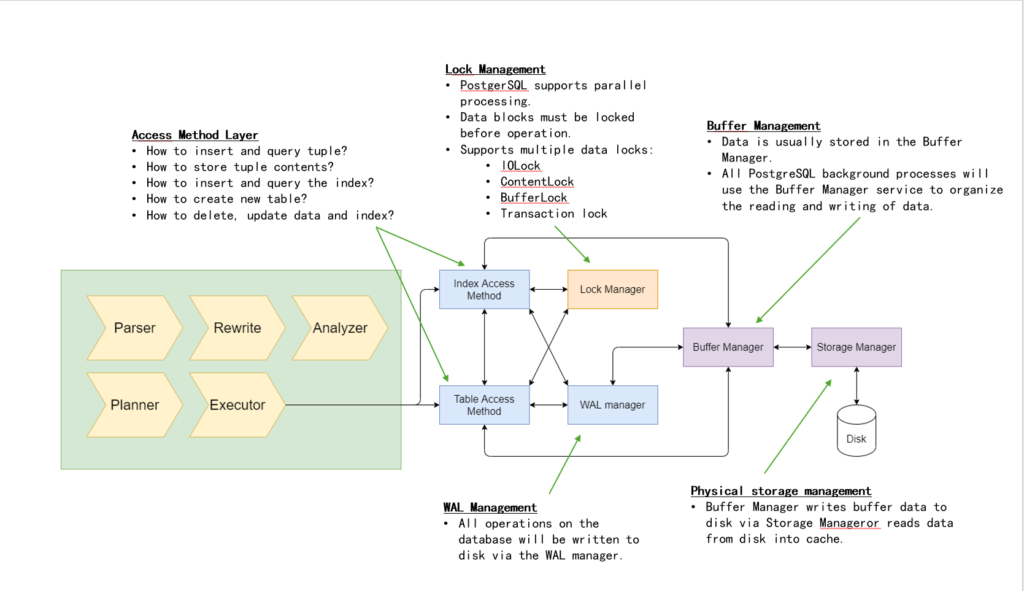
The executor module relies on several other modules to complete the query. It most likely will interface with the Access Method Layer (table and index access methods), which is responsible for the actual data manipulation (read or write) or table and index data. The access method layer will in turn relies on other modules (buffer manager and storage manager) to handle the actual data read and write. See image illustration below:
Learn more about table access method here
Query Processing Life Cycle
In terms of source code, the query processing starts by making a call to exec_simple_query() function. Most queries you issued via psql is started here unless you are using cursor or extended query protocol. Those are another topics for another day though.
From within the exec_simple_query(), it calls the entry point functions provided by each query processing stages and in the end returns DestReceiver object.
See illustration below:

Portal – DestReceiver
Regardless if the query ends up in ProcessUtility or Executor, it will eventually return one or more results. These results are stored in the structure of TupleTableSlot (TTS for short), which contains one or more Tuple as results.
Tuple can be understood as row data. There may be multiple values in a tuple, corresponding to the corresponding column. PostgreSQL currently only supports Heap as a tuple type, also called HeapTuple. The behavior of Heap is defined in HeapAccessMethod.
TTS is stored in the DestReceiver structure, which tells the Portal module where the results should be presented, marking the end of the query processing.

Cary is a Senior Software Developer in HighGo Software Canada with 8 years of industrial experience developing innovative software solutions in C/C++ in the field of smart grid & metering prior to joining HighGo. He holds a bachelor degree in Electrical Engineering from University of British Columnbia (UBC) in Vancouver in 2012 and has extensive hands-on experience in technologies such as: Advanced Networking, Network & Data security, Smart Metering Innovations, deployment management with Docker, Software Engineering Lifecycle, scalability, authentication, cryptography, PostgreSQL & non-relational database, web services, firewalls, embedded systems, RTOS, ARM, PKI, Cisco equipment, functional and Architecture Design.
Recent Comments